Competent Genetic Algorithms
The working mechanics of a genetic algorithm are derived from a simple assumption (Holland 1975) that the best solution will be found in the solution region that contains a relatively high proportion of good solutions. A set of strings that represent the good solutions attains certain similarities in bit values. For example, 3-bit binary strings 001, 111, 101 and 011 have a common similarity template of **1, where asterisk (*) denotes a don't-care symbol that takes a value of either 1 or 0. The four strings represent four good solutions and contribute to the fitness values of 10, 12, 11, and 11 to a fitness function of:
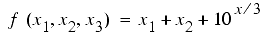
Where x1, x2, and x3 directly take a bit value as an integer from left to right. In general, a short similarity template that contributes an above-average fitness is called a building block. Building blocks are often contained in short strings that represent partial solutions to a specific problem. Thus, searching for good solutions uncovers and juxtaposes the good short strings, which essentially designate a good solution region, and finally leads a search to the best solution.
Goldberg et al. (1989) developed the messy genetic algorithm as one of the competent genetic algorithm paradigms by focusing on improving GA's capability of identifying and exchanging building blocks. The first-generation of the messy GA explicitly initializes all the short strings of a desired length k, where k is referred as to the order of a building block defined by a short string. For a binary string representation, all the combinations of order-k building blocks require a number of initial short strings of length k for an l-bit problem:

For example, the initial population size of short strings, by completely enumerating the building blocks of order 4 for a 40-bit problem, is more than one million. This made the application of the first-generation messy GA to a large-scale optimization problem impossible. This bottleneck has been overcome by introducing a building block filter procedure (Goldberg et al. 1993) into the messy GA. The filter procedure speeds up the search process and is called a fast messy GA.
The fast messy GA emulates the powerful genetic-evolutionary process in two nested loops, an outer loop and an inner loop. Each cycle of the outer loop, denoted as an era, invokes an initialization phase and an inner loop that consists of a building block filtering phase and a juxtapositional phase. Like a simple genetic algorithm, the messy GA initialization creates a population of random individuals. The population size has to be large enough to ensure the presence of all possible building blocks. Then a building block filtering procedure is applied to select better-fit short strings and reduce the string length. It works like a filter so that bad genes not belonging to building blocks are deleted, so that the population contains a high proportion of short strings of good genes. The filtering procedure continues until the overall string length is reduced to a desired length k. Finally, a juxtapositional phase follows to produce new strings. During this phase, the processed building blocks are combined and exchanged to form offspring by applying the selection and reproduction operators. The juxtapositional phase terminates when the maximum number of generations is reached, and the cycle of one era iteration completes. The length of short strings that contains desired building blocks is often specified as the same as an era, starting with one to a maximum number of era. Because of this, preferred short strings increase in length over outer iterations. In other words, a messy GA evolves solutions from short strings starting from length one to a maximum desired length. This enables the messy GA to mimic the natural and biological evolution process that a simple or one cell organism evolves into a more sophisticated and intelligent organism. Goldberg et al. (1989, 1993) has given the detail analysis and computation procedure of the messy GA.